
What exactly is Salesforce Data Skew?
If you've spent any time working on enterprise-scale orgs, you've probably run into Salesforce Data Skew without even realizing it at first. It's one of those silent killers that stays hidden until you try to run a big data load or change a sharing rule, and then suddenly, everything breaks. In simple terms, it's what happens when your data isn't distributed evenly, creating "hotspots" that the system just can't handle efficiently.
Think of it like a massive highway where every single car is trying to use the exact same exit at 5:00 PM. The highway itself is fine, but that one exit ramp becomes a total nightmare. In Salesforce, those exit ramps are specific records or users that have way too many relationships tied to them. When you hit that limit, you'll start seeing those dreaded row-lock errors that keep us all up at night.
Understanding how to manage large data volumes is a huge part of being a senior architect, but skew is a specific flavor of that challenge. Let's break down the types of skew you're likely to see in the wild.
The three main types of Salesforce Data Skew
Not all skew is created equal. Depending on how you've built your data model, you might be dealing with one of three different issues. Here's how they usually show up in a real project.
1. Ownership Skew
This is probably the most common one I see. It happens when a single user or a queue owns a massive amount of records - usually 10,000 or more. I've seen orgs where a "System User" owns 500,000 Accounts because the team didn't want to deal with ownership logic. But here's the thing: when you update those records, Salesforce has to lock the owner's record to maintain integrity. If you're doing bulk updates, you'll hit lock contention faster than you can blink.
2. Lookup Skew
Lookup skew is a specific flavor of Salesforce Data Skew that happens when thousands of child records point to the same parent record. Imagine you have a "Generic Account" and you're linking every single orphan Contact to it. Every time you add or change a Contact, Salesforce has to look at that parent Account. If that parent has too many children, the system struggles to maintain the indexes and sharing trees, leading to massive performance lags.
3. Sharing and Role Skew
This one is a bit more subtle but just as dangerous. It happens when you have too many users assigned to the same role or when your sharing rules are so concentrated that a single change triggers a massive recalculation. If you move one person at the top of a skewed hierarchy, Salesforce might have to rethink millions of sharing rows. That's when your deployments start timing out and your users start complaining that the system is "slow."
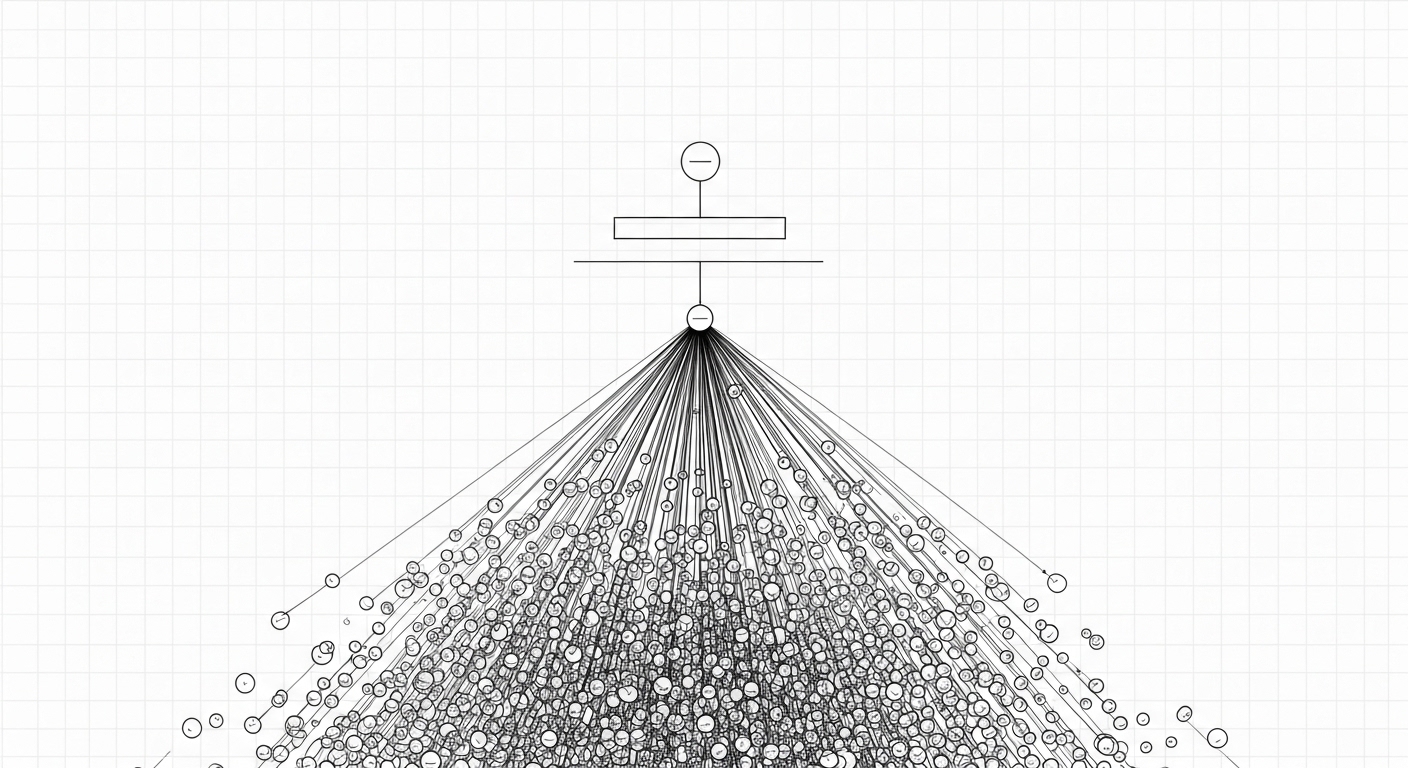
A technical architecture diagram showing a skewed data hierarchy where a single parent record is connected to a massive, dense cluster of child records.
How to spot the symptoms
So how do you know if you're actually dealing with Salesforce Data Skew? Usually, the system will tell you, but not in a very friendly way. You'll start seeing "UNABLE_TO_LOCK_ROW" errors in your integration logs or Batch Apex results. These aren't just random glitches; they're a sign that your processes are fighting over the same record.
Another red flag is when your bulk data loads start taking way longer than they used to. If a 50,000-record insert took ten minutes last month and takes an hour today, you might have a skew problem growing under the hood. You might also notice that simple updates to a parent record suddenly cause CPU spikes because of the sheer volume of child records that need to be checked.
Pro tip: If you see a single user or parent record owning 10,000 or more records, you're officially in the danger zone. That's usually the threshold where Salesforce starts to sweat during sharing recalculations.
Detecting and fixing the mess
Now, if you suspect you've got a problem, don't guess. Run some SOQL. You can use a simple "Group By" query to find the culprits. For ownership skew, try something like this in your Query Editor:
SELECT OwnerId, COUNT(Id) FROM Account GROUP BY OwnerId ORDER BY COUNT(Id) DESC LIMIT 10
For lookup skew, just swap out the field for your lookup relationship. Once you've found the hotspots, you've got to start the cleanup. The best way to fix ownership skew is to distribute the load. Use a round-robin assignment or spread records across multiple "integration users" instead of just one.
If you're stuck with lookup skew, you might need to rethink your data model. Sometimes that means creating "overflow" parent records or using Async Apex to handle updates in smaller, manageable chunks. Honestly, most teams get this wrong by trying to fix it with code when they actually need to fix the data architecture.
Key Takeaways
- Watch the 10k limit: Use that as your benchmark for when a relationship or owner is becoming a liability.
- Distribute ownership: Never let a single user own the world. Use queues or multiple service accounts.
- Pick your parents wisely: Avoid "dummy" records that act as a catch-all for lookups.
- Go Async: Use Batch or Queueable Apex to reduce the pressure on row locks during high-volume operations.
- Monitor regularly: Skew grows over time. Make it a habit to check your record distributions every few months.
Managing Salesforce Data Skew isn't just about keeping the system running; it's about building something that can actually scale as the business grows. If you're seeing those locking errors today, take it as a warning. Start looking at your distribution, run your queries, and break up those hotspots before they turn into a full-blown system outage. It's much easier to fix a skew problem while it's small than it is to re-architect a live production environment with millions of records.




Leave a Comment